Web scraping is the process of extracting data from websites using automated tools. It’s widely used in industries like e-commerce, finance, and research to collect data for analysis and decision-making. To get started, here’s what you need to know:
- Web Crawling vs. Scraping: Crawling finds web pages; scraping extracts specific data.
- HTML Parsing: Tools like Beautiful Soup and Scrapy help process web page code to extract data.
- Scraping Bots: Automate data collection but must respect rate limits to avoid detection.
- Rate Limiting: Servers restrict request rates to prevent overload or misuse.
- Proxies: Used to avoid IP bans and access restricted content.
Ethics and Legal Compliance: Always follow website rules, avoid personal data scraping, and comply with laws like GDPR. Tools like InstantAPI.ai simplify scraping while managing proxies and dynamic content.
| Tool | Best For | Limitations |
|---|---|---|
| Beautiful Soup | Static websites | Not suited for large-scale projects |
| Scrapy | Large-scale scraping | Requires setup and technical knowledge |
| Selenium | Dynamic content | Slower performance for large datasets |
| InstantAPI.ai | AI-driven, no-code scraping | Paid plans for advanced features |
Learn the basics, pick the right tools, and always scrape responsibly.
Important Web Scraping Terms
Web Crawling and Web Scraping: The Difference
Web crawling involves systematically navigating websites to discover and index pages, much like how search engines explore the web. On the other hand, web scraping focuses on extracting specific data points from targeted pages for analysis. Crawling helps identify data sources, while scraping pulls the information you need, often using HTML parsing to process the data.
What is HTML Parsing?
HTML parsing transforms web page code into a structured format, making it easier to extract elements such as prices or contact information. Popular tools for this process include Beautiful Soup and Scrapy, which simplify the task of locating and extracting data.
What Are Scraping Bots?
Scraping bots are automated tools designed to extract specific data from websites. They are widely used across industries to collect information such as flight prices, product reviews, or property listings.
| Industry | Bot Application | Data Collected |
|---|---|---|
| Travel | Price Monitoring | Flight prices, hotel rates, availability |
| E-commerce | Market Analysis | Product details, pricing, reviews |
| Finance | Market Intelligence | Stock prices, financial reports, trends |
| Real Estate | Property Data | Listings, prices, property details |
While helpful, scraping bots must be managed carefully to prevent triggering server defenses like rate limiting.
What is Rate Limiting?
Rate limiting controls how many requests a client can make to a server within a specific time frame. For example, a server might allow only 100 requests per hour per IP address. This measure prevents server overload and ensures fair access for all users.
How Does Data Extraction Work?
Data extraction focuses on identifying and collecting specific information from web pages, such as product details or flight prices. It involves analyzing the website's structure and using the right tools to gather data effectively. Staying within rate limits and respecting terms of service is crucial to ensure ethical and responsible web scraping.
Methods and Tools for Web Scraping
Manual vs. Automated Scraping
Manual scraping is as simple as copying data directly from a website, making it a good fit for small, straightforward tasks. Automated scraping, however, relies on tools to gather large volumes of data quickly, making it ideal for more complex or recurring projects.
| Scraping Method | Best For | Limitations |
|---|---|---|
| Manual | Small datasets, simple structures, one-time tasks | Time-intensive, prone to errors, not scalable |
| Automated | Large-scale data, recurring needs, complex sites | Requires technical skills, takes time to set up |
When dealing with dynamic websites, automated tools like headless browsers are often a necessity to handle the complexities.
Using Headless Browsers for Scraping
Headless browsers, such as Puppeteer and Selenium, make scraping JavaScript-heavy sites easier by simulating user actions without displaying a visual interface. Puppeteer is particularly good at managing dynamic content, while Selenium is more versatile for broader testing needs. While these tools tackle dynamic content effectively, proxies are often needed to ensure uninterrupted access.
Why Proxies Are Used in Scraping
Proxies act as a go-between for your scraping tool and the target site, helping you avoid IP bans and access issues. Residential proxies are especially useful because they mimic regular user devices, lowering the chances of detection. To use proxies effectively, it's important to rotate them, choose the right geographic locations, and find a balance between speed and cost.
Platforms like InstantAPI.ai combine AI and proxies for smooth data extraction, ensuring reliable results while adhering to website terms of service.
Ethics and Legal Rules in Web Scraping
Ethical Guidelines for Web Scraping
Scraping data from websites comes with responsibilities. Ethical web scraping means following website rules, protecting user privacy, and ensuring fair use of data. These practices help safeguard both website owners and users.
The first step is to respect website rules, such as those outlined in robots.txt files and Terms of Service, which detail what can and cannot be scraped. Following these rules ensures that your data collection does not disrupt website functionality or user access.
| Ethical Practice | Purpose | Benefit |
|---|---|---|
| Compliance with Website Rules | Respect access policies | Keeps websites stable |
| Privacy Protection | Avoid collecting personal data | Safeguards user information |
| Fair Usage | Use proper access controls | Maintains website performance |
Legal Risks and Compliance
Web scraping exists in a legal gray area influenced by laws like the CFAA and GDPR. Cases such as hiQ Labs v. LinkedIn highlight the need to understand data access rights and secure proper permissions.
Key areas to focus on include:
- Copyright and Intellectual Property: Avoid scraping content protected by copyright without permission.
- Privacy and Data Protection Laws: Follow regulations like GDPR, which require consent for collecting personal data and secure handling of sensitive information.
- Terms and Conditions: Always check website-specific rules before scraping.
For GDPR compliance, you must obtain user consent when collecting personal data, store it securely, and clearly explain how it will be used. Handling sensitive data may require extra security measures and adherence to stricter regulations.
Whenever possible, use APIs provided by websites for data access. If APIs aren’t available, ensure your scraping practices align with the law. Following these guidelines not only reduces legal risks but also helps you work more effectively with tools and platforms designed for proper data extraction.
sbb-itb-f2fbbd7
Related video from YouTube
Web Scraping Tools and Platforms
Web scraping tools have come a long way, making data extraction easier for both beginners and seasoned developers. These tools offer everything from simple HTML parsing to advanced, automated solutions.
Using InstantAPI.ai
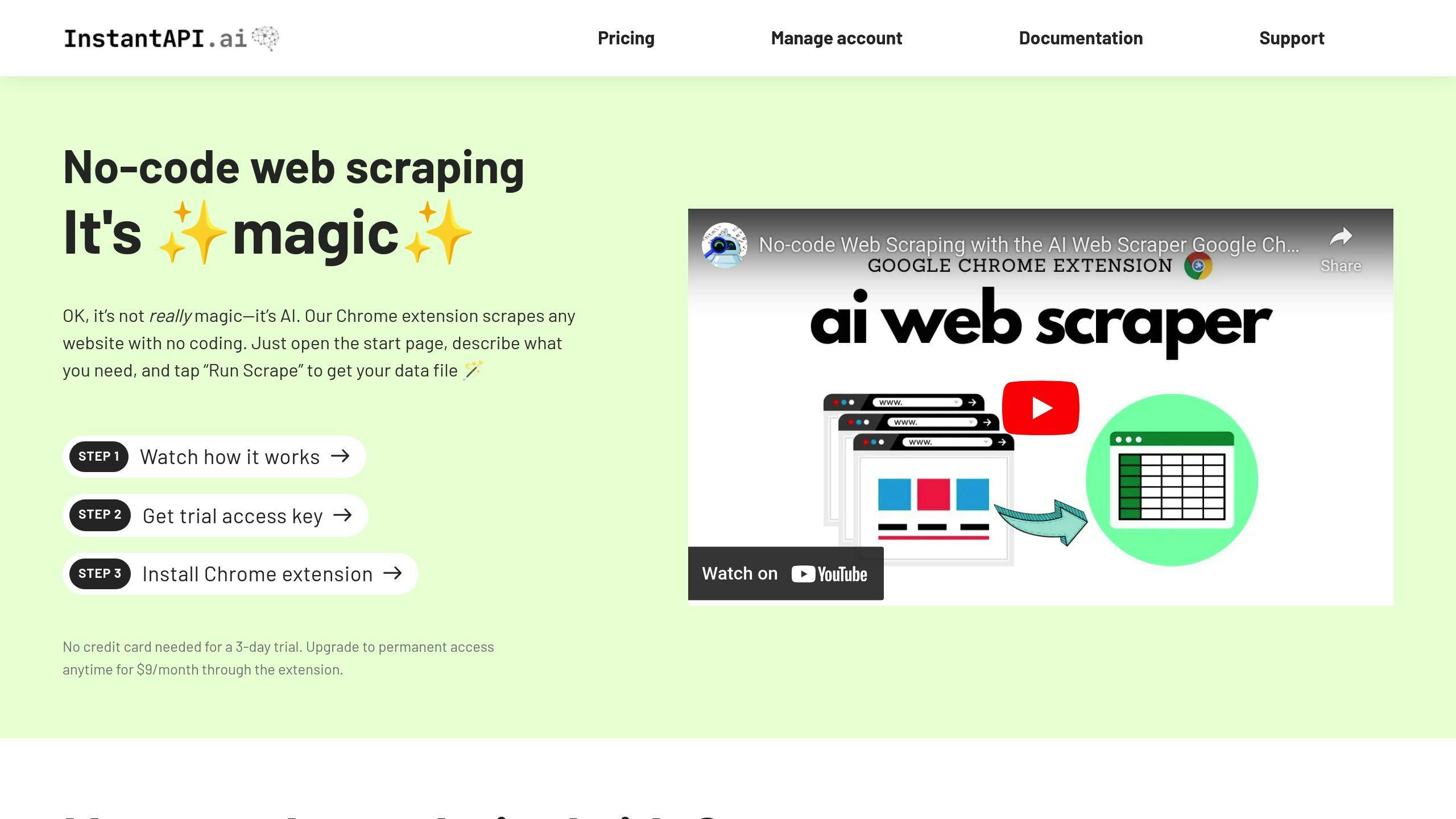
InstantAPI.ai simplifies scraping with its AI-driven platform. It tackles tricky tasks like rendering JavaScript, rotating proxies, and extracting data without needing complex configurations. Its built-in proxy management ensures smooth access to dynamic content.
| Feature | Purpose | Ideal For |
|---|---|---|
| AI Automation | Handles dynamic content reliably | Complex websites |
| JavaScript Rendering | Accesses interactive content | Single-page applications |
| Premium Proxies | Ensures uninterrupted scraping | High-volume projects |
The platform offers a free tier for basic tasks and scalable paid plans for enterprise needs. Features like premium proxies and unlimited concurrent requests make it suitable for a variety of scraping scenarios.
Other Commonly Used Tools
Some traditional tools remain highly effective for specific tasks:
- Beautiful Soup: Great for parsing static websites.
- Scrapy: Ideal for large-scale projects with robust infrastructure.
- Selenium: Perfect for handling dynamic content and simulating user actions.
"Web scraping is a powerful tool for data analysis and research, but it requires a certain level of technical expertise and understanding of ethical and legal considerations." - V. Krotov, L. Johnson, & L. Silva, Tutorial: Legality and Ethics of Web Scraping
When picking a tool, think about:
- Project Size: Beautiful Soup works for small tasks, while Scrapy suits larger projects.
- Website Type: For dynamic content, tools like Selenium or headless browsers are better.
- Skill Level: Some tools need coding expertise, while others, like InstantAPI.ai, offer no-code options.
While InstantAPI.ai provides a modern, AI-powered solution, traditional tools like Beautiful Soup and Selenium remain essential for more specific needs. Mastering these tools lets you extract data effectively while staying within ethical boundaries.
Summary and Next Steps
Key Takeaways
Understanding concepts like HTML parsing, rate limiting, and bot management is crucial for ethical and effective web scraping. These practices not only help you collect data efficiently but also ensure you respect website resources and follow guidelines. Knowing the difference between web crawling (finding URLs) and web scraping (extracting specific data) allows you to choose the right method for your goals.
Expanding Your Knowledge
Web scraping techniques and tools are constantly changing, so staying informed is critical. Platforms like DataCamp and Coursera offer courses that cover both basic and advanced web scraping methods. The Web Scraping subreddit is another great place to discuss challenges and find solutions within a community of peers.
Start by learning tools like Beautiful Soup for simpler, static websites. Once you're comfortable, explore more advanced tools. The NNLM guide on web scraping ethics and legality is a must-read to ensure compliance with legal and ethical standards. Reviewing case studies and legal updates regularly will help you stay aligned with industry norms.
Engage with web scraping communities and follow industry blogs to keep up with:
- New tools and techniques
- Best practices for data validation
- Ethical standards
- Updates on legal regulations


